佐藤研究室/菅野研究室
佐藤研究室/菅野研究室
佐藤 (洋) 研究室
菅野研究室
ニュース
発表文献
連絡先
リソース
内部ページ
日本語
English
Paper-Conference
Domain Adaptive Hand Keypoint and Pixel Localization in the Wild
We aim to improve the performance of regressing hand keypoints and segmenting pixel-level hand masks under new imaging conditions …
Takehiko Ohkawa
,
Yu-Jhe Li
,
Qichen Fu
,
Ryosuke Furuta
,
Kris Kitani
,
Yoichi Sato
PDF
引用
DOI
Surgical Skill Assessment via Video Semantic Aggregation
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in …
Zhenqiang Li
,
Ling Gu
,
Weimin Wang
,
Ryosuke Nakamura
,
Yoichi Sato
PDF
引用
ソースコード
DOI
Learning-by-Novel-View-Synthesis for Full-Face Appearance-Based 3D Gaze Estimation
Despite recent advances in appearance-based gaze estimation techniques, the need for training data that covers the target head pose and …
Jiawei Qin
,
Takuru Shimoyama
,
Yusuke Sugano
PDF
引用
プロジェクト
DOI
Ego4D: Around the World in 3,000 Hours of Egocentric Video
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,670 hours of daily-life activity video …
Kristen Grauman
,
Andrew Westbury
,
Eugene Byrne
,
Zachary Chavis
,
Antonino Furnari
,
Rohit Girdhar
,
Jackson Hamburger
,
Hao Jiang
,
Miao Liu
,
Xingyu Liu
,
Miguel Martin
,
Tushar Nagarajan
,
Ilija Radosavovic
,
Santhosh Kumar Ramakrishnan
,
Fiona Ryan
,
Jayant Sharma
,
Michael Wray
,
Mengmeng Xu
,
Eric Zhongcong Xu
,
Chen Zhao
,
Siddhant Bansal
,
Dhruv Batra
,
Vincent Cartillier
,
Sean Crane
,
Tien Do
,
Morrie Doulaty
,
Akshay Erapalli
,
Christoph Feichtenhofer
,
Adriano Fragomeni
,
Qichen Fu
,
Abrham Gebreselasie
,
Cristina Gonzalez
,
James Hillis
,
Xuhua Huang
,
Yifei Huang
,
Wenqi Jia
,
Weslie Khoo
,
Jachym Kolar
,
Satwik Kottur
,
Anurag Kumar
,
Federico Landini
,
Chao Li
,
Yanghao Li
,
Zhenqiang Li
,
Karttikeya Mangalam
,
Raghava Modhugu
,
Jonathan Munro
,
Tullie Murrell
,
Takumi Nishiyasu
,
Will Price
,
Paola Ruiz Puentes
,
Merey Ramazanova
,
Leda Sari
,
Kiran Somasundaram
,
Audrey Southerland
,
Yusuke Sugano
,
Ruijie Tao
,
Minh Vo
,
Yuchen Wang
,
Xindi Wu
,
Takuma Yagi
,
Ziwei Zhao
,
Yunyi Zhu
,
Pablo Arbelaez
,
David Crandall
,
Dima Damen
,
Giovanni Maria Farinella
,
Christian Fuegen
,
Bernard Ghanem
,
Vamsi Krishna Ithapu
,
C. v. Jawahar
,
Hanbyul Joo
,
Kris Kitani
,
Haizhou Li
,
Richard Newcombe
,
Aude Oliva
,
Hyun Soo Park
,
James M. Rehg
,
Yoichi Sato
,
Jianbo Shi
,
Mike Zheng Shou
,
Antonio Torralba
,
Lorenzo Torresani
,
Mingfei Yan
,
Jitendra Malik
PDF
引用
DOI
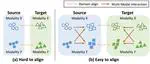
Interact before Align: Leveraging Cross-Modal Knowledge for Domain Adaptive Action Recognition
Unsupervised domain adaptive video action recognition aims to recognize actions of a target domain using a model trained with only …
Lijin Yang
,
Yifei Huang
,
Yusuke Sugano
,
Yoichi Sato
PDF
引用
DOI
Object Instance Identification in Dynamic Environments
We study the problem of identifying object instances in a dynamic environment where people interact with the objects. In such an …
Takuma Yagi
,
Md Tasnimul Hasan
,
Yoichi Sato
PDF
引用
Precise Affordance Annotation for Egocentric Action Video Datasets
Object affordance is an important concept in human-object interaction, providing information on action possibilities based on human …
Zecheng Yu
,
Yifei Huang
,
Ryosuke Furuta
,
Takuma Yagi
,
Yusuke Gotsu
,
Yoichi Sato
PDF
引用
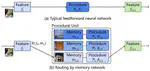
Neural Routing by Memory
Recent Convolutional Neural Networks (CNNs) have achieved significant success by stacking multiple convolutional blocks, named …
Kaipeng Zhang
,
Zhenqiang Li
,
Zhifeng Li
,
Wei Liu
,
Yoichi Sato
PDF
引用
Hand-Object Contact Prediction via Motion-Based Pseudo-Labeling and Guided Progressive Label Correction
Every hand-object interaction begins with contact. Despite predicting the contact state between hands and objects is useful in …
Takuma Yagi
,
Md Tasnimul Hasan
,
Yoichi Sato
PDF
引用
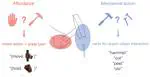
Leveraging Human Selective Attention for Medical Image Analysis with Limited Training Data
The human gaze is a cost-efficient physiological data that reveals human underlying attentional patterns. The selective attention …
Yifei Huang
,
Xiaoxiao Li
,
Lijin Yang
,
Lin Gu
,
Yingying Zhu
,
Hirofumi Seo
,
Qiuming Meng
,
Tatsuya Harada
,
Yoichi Sato
PDF
引用
«
»
引用
×