Learning-by-Novel-View-Synthesis for Full-Face Appearance-Based 3D Gaze Estimation
概要
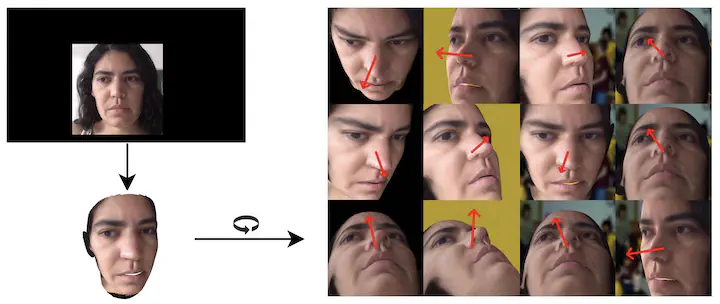
Despite recent advances in appearance-based gaze estimation techniques, the need for training data that covers the target head pose and gaze distribution remains a crucial challenge for practical deployment. This work examines a novel approach for synthesizing gaze estimation training data based on monocular 3D face reconstruction. Unlike prior works using multi-view reconstruction, photorealistic CG models, or generative neural networks, our approach can manipulate and extend the head pose range of existing training data without any additional requirements. We introduce a projective matching procedure to align the reconstructed 3D facial mesh with the camera coordinate system and synthesize face images with accurate gaze labels. We also propose a mask-guided gaze estimation model and data augmentation strategies to further improve the estimation accuracy by taking advantage of synthetic training data. Experiments using multiple public datasets show that our approach significantly improves the estimation performance on challenging cross-dataset settings with non-overlapping gaze distributions.