佐藤研究室/菅野研究室
佐藤研究室/菅野研究室
佐藤 (洋) 研究室
菅野研究室
ニュース
発表文献
連絡先
リソース
内部ページ
日本語
English
最近の発表文献
» 全発表文献リスト
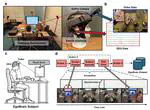
Embodied Interaction with Large Language Models: A Spatio-Physical Approach for Engaging Non-technical Users
Despite their growing capabilities, large language models (LLMs) remain unfamiliar to many non-technical users. The true potential of …
Hiroto Fukuda
,
Wataru Kawabe
,
Yusuke Sugano
PDF
引用
DOI
Constrained Rotation Optimization: Revisiting Crop-Based Gaze Estimation
Appearance-based gaze estimation typically relies on face normalization to reduce appearance variability, but this requires costly and …
Riccardo Santambrogio
,
Jiawei Qin
,
Matteo Matteucci
,
Yusuke Sugano
PDF
引用
ソースコード
Prosthesis-Aware 3D Human Pose Estimation: A Dataset and Benchmark for RSP Users
Recovering 3D human body motion from video is important for applications such as rehabilitation assessment and sports performance …
Yilin Wen
,
Kechuan Dong
,
Fumiya Suginaka
,
Ken Endo
,
Yusuke Sugano
引用
プロジェクト
Multiagent First-Person Perspective Analysis for Leadership Assessment in Pediatric Emergency Simulations: A Feasibility Study
Conventional leadership assessments provide structured ratings but offer limited observer-independent metrics. Because leadership and …
Hisataka Nozawa
,
Ayumi Kunikata
,
Yuki Sakai
,
Liangyang Ouyang
,
Ryosuke Furuta
,
Yoichi Sato
,
Hikoro Matsui
PDF
引用
DOI
Exploring a Collaborative Gamified Approach to Vision-Language Model Evaluation
Vision-language models demonstrate impressive capabilities, yet constructing evaluation datasets that capture their failure cases still …
Fan Gao
,
Jenna Ren Mei Wang
,
Tomomi Sayuda
,
Miles Pennington
,
Yusuke Sugano
PDF
引用
DOI
TofuML: A Spatio-Physical Interactive Machine Learning Device for Interactive Exploration of Machine Learning for Novices
We introduce TofuML, an interactive system designed to make machine learning (ML) concepts more accessible and engaging for non-expert …
Wataru Kawabe
,
Hiroto Fukuda
,
Akihisa Shitara
,
Yuri Nakao
,
Yusuke Sugano
PDF
引用
DOI
EgoBrain: Synergizing Minds and Eyes For Human Action Understanding
The integration of brain-computer interfaces (BCIs), in particular electroencephalography (EEG), with artificial intelligence (AI) has …
Nie Lin
,
Yansen Wang
,
Dongqi Han
,
Weibang Jiang
,
Jingyuan Li
,
Ryosuke Furuta
,
Yoichi Sato
,
Dongsheng Li
引用
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, …
Yuping He
,
Yifei Huang
,
Guo Chen
,
Lidong Lu
,
Baoqi Pei
,
Jilan Xu
,
Tong Lu
,
Yoichi Sato
引用
UniGaze: Towards Universal Gaze Estimation via Large-scale Pre-Training
Despite decades of research on data collection and model architectures, current gaze estimation models encounter significant challenges …
Jiawei Qin
,
Xucong Zhang
,
Yusuke Sugano
PDF
引用
ソースコード
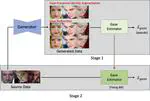
Learning-by-Generation: Enhancing Gaze Estimation via Controllable Generative Data and Two-Stage Training
Generalization to unseen environments is crucial in appearance-based gaze estimation but is primarily hindered by limitations in …
Jiawei Qin
,
Xueting Wang
,
Yusuke Sugano
PDF
引用
DOI
発表文献一覧
引用
×