概要
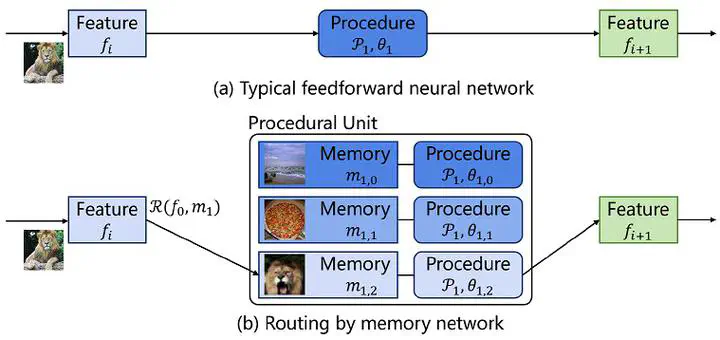
Recent Convolutional Neural Networks (CNNs) have achieved significant success by stacking multiple convolutional blocks, named procedures in this paper, to extract semantic features. However, they use the same procedure sequence for all inputs, regardless of the intermediate features.This paper proffers a simple yet effective idea of constructing parallel procedures and assigning similar intermediate features to the same specialized procedures in a divide-and-conquer fashion. It relieves each procedure’s learning difficulty and thus leads to superior performance. Specifically, we propose a routing-by-memory mechanism for existing CNN architectures. In each stage of the network, we introduce parallel Procedural Units (PUs). A PU consists of a memory head and a procedure. The memory head maintains a summary of a type of features. For an intermediate feature, we search its closest memory and forward it to the corresponding procedure in both training and testing. In this way, different procedures are tailored to different features and therefore tackle them better.Networks with the proposed mechanism can be trained efficiently using a four-step training strategy. Experimental results show that our method improves VGGNet, ResNet, and EfficientNet’s accuracies on Tiny ImageNet, ImageNet, and CIFAR-100 benchmarks with a negligible extra computational cost.