Cross-View Correspondence Modeling for Joint Representation Learning Between Egocentric and Exocentric Videos
Abstract
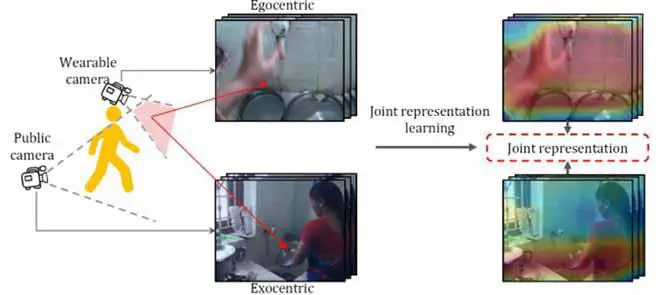
Joint analysis of human action videos from egocentric and exocentric views enables a more comprehensive understanding of human behavior. While previous works leverage paired videos to align clip-level features across views, they often ignore the complex spatial and temporal misalignments inherent in such data. In this work, we propose a Cross-View Transformer that explicitly models fine-grained spatiotemporal correspondence between egocentric and exocentric videos. Our model incorporates self-attention to enhance intra-view context and cross-view attention to align features across space and time. To train the model, we introduce a hybrid loss function combining a triplet loss and a domain classification loss, further reinforced by a sample screening mechanism that emphasizes informative training pairs. We evaluate our method on multiple egocentric action recognition benchmarks, including Charades-Ego and EPIC-Kitchens. Experimental results demonstrate that our method consistently outperforms existing approaches, achieving state-of-the-art performance on several egocentric video understanding tasks.