HanDyVQA: A Video QA Benchmark for Fine-Grained Hand-Object Interaction Dynamics
Abstract
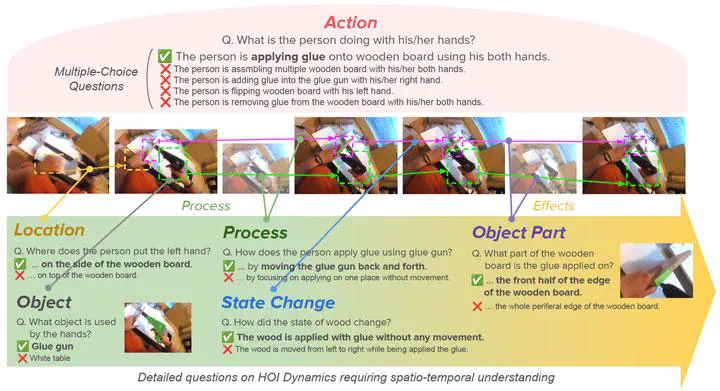
Hand-Object Interaction (HOI) is inherently a dynamic process, involving nuanced spatial coordination, diverse manipulation styles, and influences on interacting objects. However, existing HOI benchmarks tend to emphasize highlevel action recognition and hand/object localization while neglecting the fine-grained aspects of hand-object dynamics. We introduce HanDyVQA , a video question-answering benchmark for understanding the fine-grained spatiotemporal dynamics in hand-object interactions. HanDyVQA consists of six types of questions (Action, Process, Objects, Location, State Change, and Object Parts), totaling 11.7k multiple-choice question-answer pairs and 11k instance segmentations that require discerning fine-grained action contexts, hand-object movements, and state changes caused by manipulation. We evaluate several video foundation models on our benchmark to identify existing challenges and reveal that current models struggle with component-level geometric understanding, achieving a average accuracy of only 68% in Qwen2.5-VL-72B.