Interact before Align: Leveraging Cross-Modal Knowledge for Domain Adaptive Action Recognition
Abstract
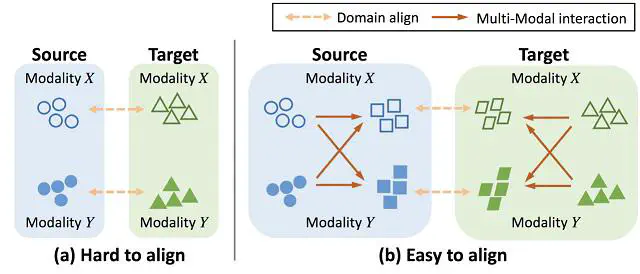
Unsupervised domain adaptive video action recognition aims to recognize actions of a target domain using a model trained with only out-of-domain (source) annotations. The inherent complexity of videos makes this task challenging but also provides ground for leveraging multi-modal inputs (e.g., RGB, Flow, Audio). Most previous works utilize the multi-modal information by either aligning each modality individually or learning representation via cross-modal self-supervision. Different from previous works, we find that the cross-domain alignment can be more effectively done by using cross-modal interaction first. Cross-modal knowledge interaction allows other modalities to supplement missing transferable information because of the cross-modal complementarity. Also, the most transferable aspects of data can be highlighted using cross-modal consensus. In this work, we present a novel model that jointly considers these two characteristics for domain adaptive action recognition. We achieve this by implementing two modules, where the first module exchanges complementary transferable information across modalities through the semantic space, and the second module finds the most transferable spatial region based on the consensus of all modalities. Extensive experiments validate that our proposed method can significantly outperform state-of-the-art methods on multiple benchmark datasets, including the complex fine-grained dataset EPIC-Kitchens-100.