Abstract
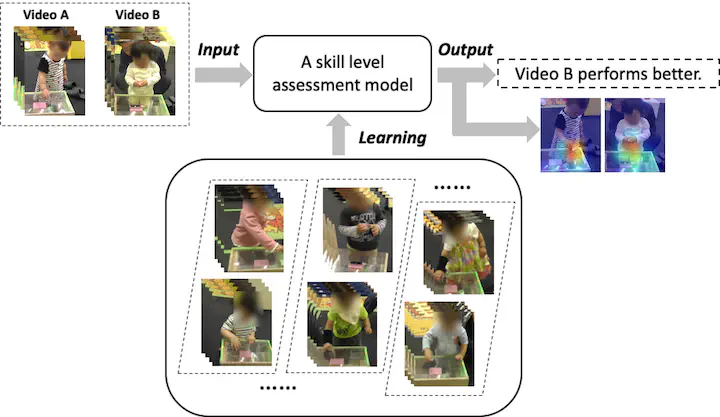
Recent advances in computer vision have made it possible to automatically assess from videos the manipulation skills of humans in performing a task, which breeds many important applications in domains such as health rehabilitation and manufacturing. Previous methods of video-based skill assessment did not consider the spatial attention mechanism humans use in assessing videos, limiting their performance as only a small part of video regions is informative for skill assessment. Our motivation here is to estimate attention in videos that helps to focus on critically important video regions for better skill assessment. In particular, we propose a novel RNN-based spatial attention model that considers accumulated attention state from previous frames as well as high-level information about the progress of an undergoing task. We evaluate our approach on a newly collected dataset of infant grasping task and four existing datasets of hand manipulation tasks. Experiment results demonstrate that state-of-the-art performance can be achieved by considering attention in automatic skill assessment.