Rotation-Constrained Cross-View Feature Fusion for Multi-View Appearance-based Gaze Estimation
概要
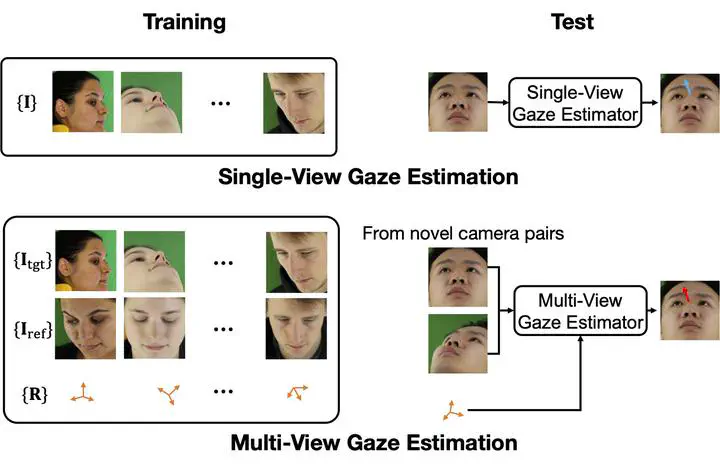
Appearance-based gaze estimation has been actively studied in recent years. However, its generalization performance for unseen head poses is still a significant limitation for existing methods. This work proposes a generalizable multi-view gaze estimation task and a cross-view feature fusion method to address this issue. In addition to paired images, our method takes the relative rotation matrix between two cameras as additional input. The proposed network learns to extract rotatable feature representation by using relative rotation as a constraint and adaptively fuses the rotatable features via stacked fusion modules. This simple yet efficient approach significantly improves generalization performance under unseen head poses without significantly increasing computational cost. The model can be trained with random combinations of cameras without fixing the positioning and can generalize to unseen camera pairs during inference. Through experiments using multiple datasets, we demonstrate the advantage of the proposed method over baseline methods, including state-of-the-art domain generalization approaches.