概要
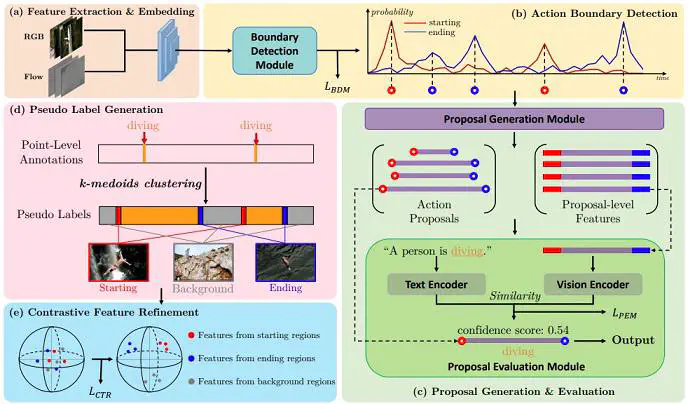
Point-level supervised temporal action localization (PTAL) aims at recognizing and localizing actions in untrimmed videos where only a single point (frame) within every action instance is annotated in training data. Without temporal annotations, most previous works adopt the multiple instance learning (MIL) framework, where the input video is segmented into non-overlapped short snippets, and action classification is performed independently on every short snippet. We argue that the MIL framework is suboptimal for PTAL because it operates on separated short snippets that contain limited temporal information. Therefore, the classifier only focuses on several easy-to-distinguish snippets instead of discovering the whole action instance without missing any relevant snippets. To alleviate this problem, we propose a novel method that localizes actions by generating and evaluating action proposals of flexible duration that involve more comprehensive temporal information. Moreover, we introduce an efficient clustering algorithm to efficiently generate dense pseudo labels that provide stronger supervision, and a fine-grained contrastive loss to further refine the quality of pseudo labels. Experiments show that our proposed method achieves competitive or superior performance to the state-of-the-art methods and some fully-supervised methods on four benchmarks: ActivityNet 1.3, THUMOS 14, GTEA, and BEOID datasets.