概要
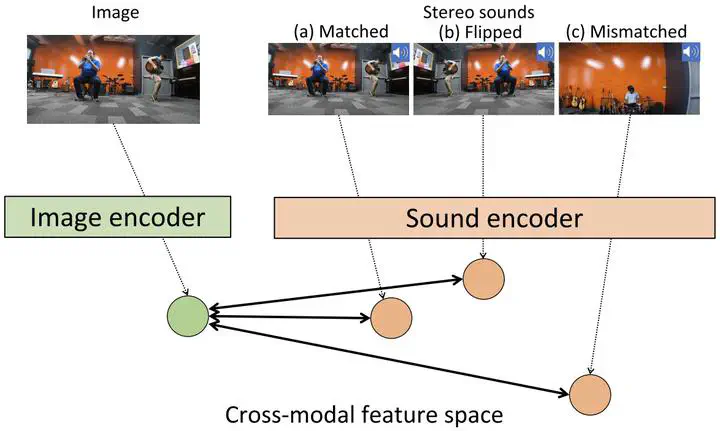
Learning cross-modal features is an essential task for many multimedia applications such as sound localization, audio-visual alignment, and image/audio retrieval. Most existing methods mainly focus on the semantic correspondence between videos and monaural sounds, and spatial information of sound sources has not been considered. However, sound locations are critical for understanding the sound environment. To this end, it is necessary to acquire cross-modal features that reflect the semantic and spatial relationship between videos and sounds. A video with stereo sound, which has become commonly used, provides the direction of arrival of each sound source in addition to the category information. This indicates its potential to acquire a desired cross-modal feature space. In this paper, we propose a novel self-supervised approach to learn a cross-modal feature representation that captures both the category and location of each sound source using stereo sound as input. For a set of unlabeled videos, the proposed method generates three kinds of audio-visual pairs: 1) perfectly matched pairs from the same video, 2) pairs from the same video but with the flipped stereo sound, and 3) pairs from a different video. The cross-modal feature encoder of the proposed method is trained on triplet loss to reflect the relationship between these three pairs ( 1>2>3 ). We apply this method to cross-modal image/audio retrieval. Compared with previous audio-visual pretext tasks, the proposed method shows significant improvement in both real and synthetic datasets.