概要
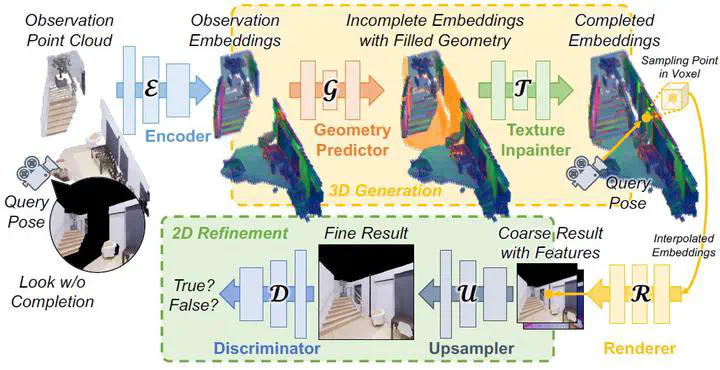
We introduce a scalable framework for novel view synthesis (NVS) from RGB-D images with largely incomplete scene coverage. While generative neural approaches have demonstrated spectacular scene completion results on 2D images, they have not yet achieved similar photorealistic results in combination with NVS for which a spatial 3D scene understanding is essential. To this end we propose a sparse grid-based neural scene representation which is learned with a generative component to complete unobserved scene parts via a learned distribution of plausible scenes. We process encoded image features in 3D space with a geometry prediction network and a subsequent texture completion network. To keep the computational cost viable, consistency-relevant 3D operations are performed on a moderate resolution which is subsequently upsampled in the 2D domain after differentiable rendering. A 2D discriminator governs the training of the entire 2.5D-to-3D-to-2.5D pipeline in a fully end-to-end manner. The graphical outputs of our method outperform state-of-the-art NVS methods especially within unobserved scene parts.