概要
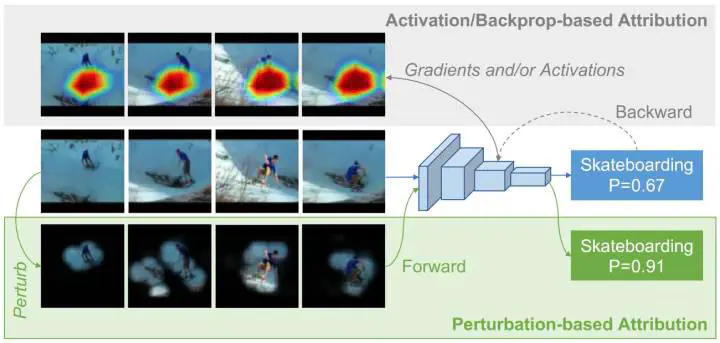
‘‘Making black box models explainable’’ is a vital problem that accompanies the development of deep learning networks. For networks taking visual information as input, one basic but challenging explanation method is to identify and visualize the input pixels/regions that dominate the network’s prediction. However, most existing works focus on explaining networks taking a single image as input and do not consider the temporal relationship that exists in videos. Providing an easy-to-use visual explanation method that is applicable to diversified structures of video understanding networks still remains an open challenge. In this paper, we investigate a generic perturbation-based method for visually explaining video understanding networks. Besides, we propose a novel loss function to enhance the method by constraining the smoothness of its results in both spatial and temporal dimensions. The method enables the comparison of explanation results between different network structures to become possible and can also avoid generating the pathological adversarial explanations for video inputs. Experimental comparison results verified the effectiveness of our method.