概要
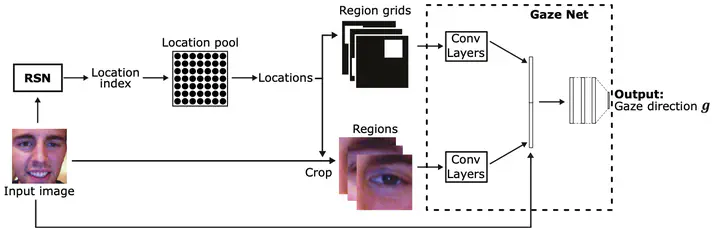
Traditionally, appearance-based gaze estimation methods use statically defined face regions as input to the gaze estimator, such as eye patches, and therefore suffer from difficult lighting conditions and extreme head poses for which these regions are often not the most informative with respect to the gaze estimation task. We posit that facial regions should be selected dynamically based on the image content and propose a novel gaze estimation method that combines the task of region proposal and gaze estimation into a single end-to-end trainable framework. We introduce a novel loss that allows for unsupervised training of a region proposal network alongside the (supervised) training of the final gaze estimator. We show that our method can learn meaningful region selection strategies and outperforms fixed region approaches. We further show that our method performs particularly well for challenging cases, i.e., those with difficult lighting conditions such as directional lights, extreme head angles, or self-occlusion. Finally, we show that the proposed method achieves better results than the current state-of-the-art method in within and cross-dataset evaluations.