概要
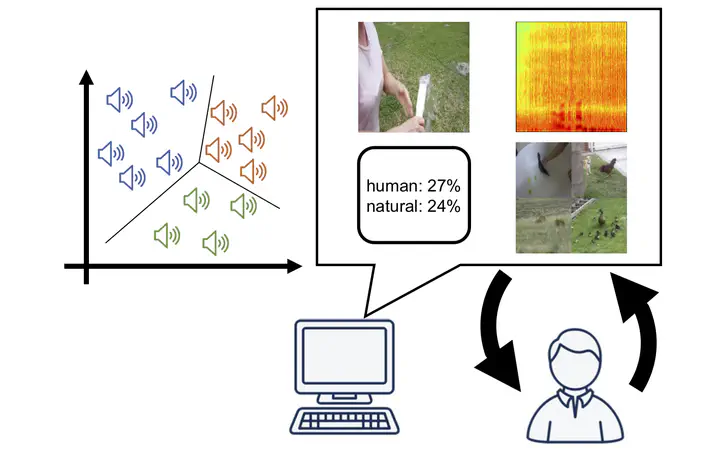
Interactive machine learning techniques have a great potential to personalize media recognition models for each individual user by letting them browse and annotate a large amount of training data. However, graphical user interfaces (GUIs) for interactive machine learning have been mainly investigated in image and text recognition scenarios, not in other data modalities such as sound. In a scenario where users browse a large amount of audio files to search and annotate target samples corresponding to their own sound recognition classes, it is difficult for them to easily navigate through the overall sample structure due to the non-visual nature of audio data. In this work, we investigate the design issue for interactive sound recognition by comparing different visualization techniques ranging from audio spectrograms to deep learning-based audio-to-image retrieval. Based on an analysis of the user study, we clarify the advantages and disadvantages of audio visualization techniques, and provide design implications for interactive sound recognition GUIs using a massive amount of audio samples.